《Paper Reading》Igniting Language Intelligence-The Hitchhiker’s Guide From Chain-of-Thought Reasoning to Language Agents
What CoT?

指令(Instruction):告知大模型的输出格式
逻辑依据(Rationale):CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识
示例(Exemplars):few shot(若无则为zero shot,加一个Let's think step by step)
When & Why CoT?
已被验证的一些经验
适用场景:
LLM
complex inference任务
参数量增加无法带来提升
不适用的场景:
- simple任务
- LLM参数量太小
性能影响因素
- Exemplars之间的相关性
- Exemplars和任务的相关性
- Rationale和Exemplars的关系
CoT 的作用,或许在于引导模型进行推理,不在于让模型拥有推理的能力
CoT Progress?
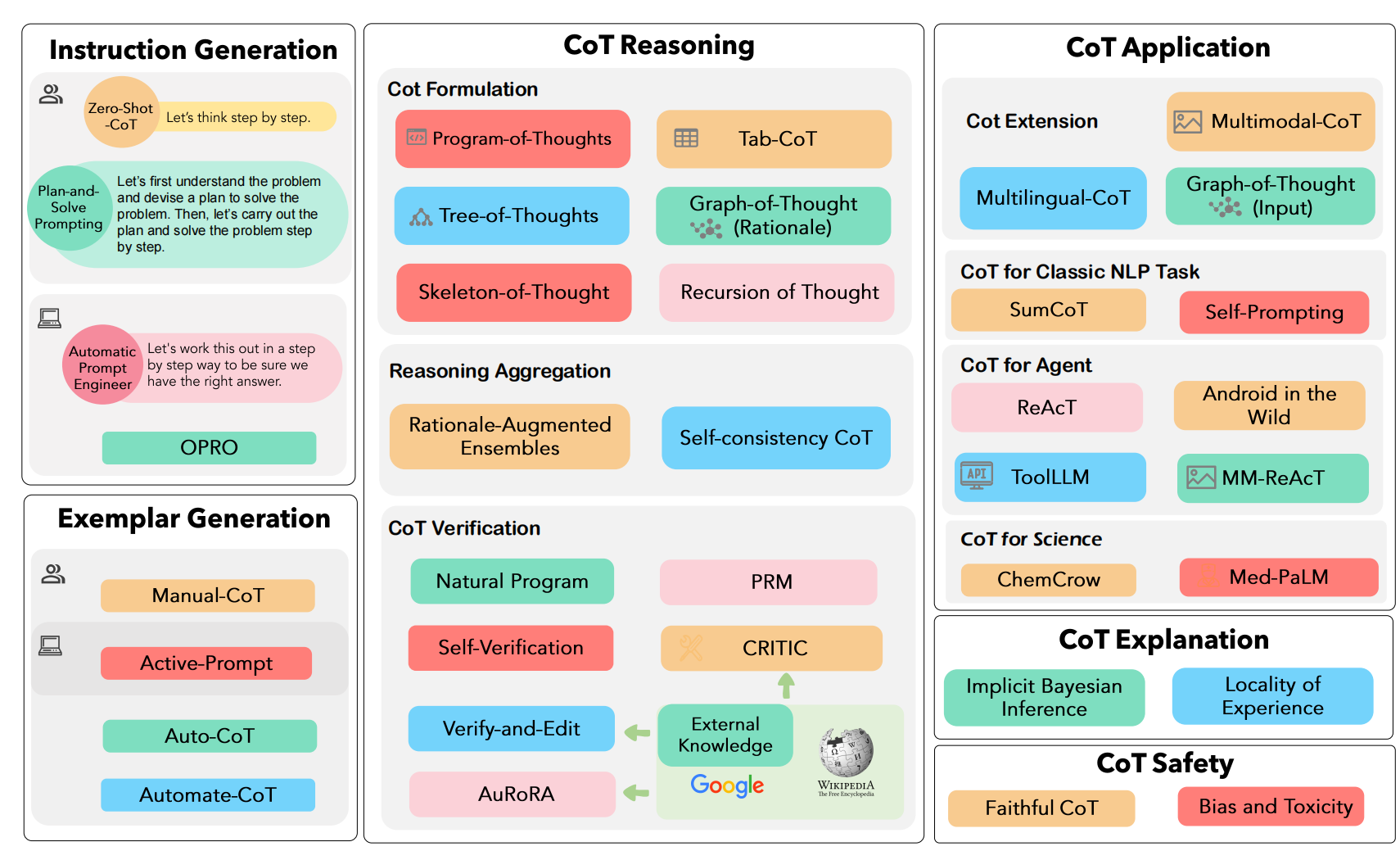
Prompt
instruction generation
手动指令生成:
- “Let's think step by step”
- Plan-and-Solve :任务分解为更小的任务
自动指令生成
- APE
- OPRO
APE 与 OPRO 的核心思想都在于设计了一套机制让大模型通过观察各个候选的 Prompt 的实际任务中的表现,通过最大化表现得分来自动选择最优的 Prompt
Exemplars generation
手动示例生成
- Few-Shot-CoT
自动示例生成
- Auto-CoT
- 问题聚类,对任务数据集进行聚类
- 示例采样:从每个聚类中心中选择一个代表性问题使用 Zero-Shot-CoT 生成思维链作为示例。
Inference
CoT structure
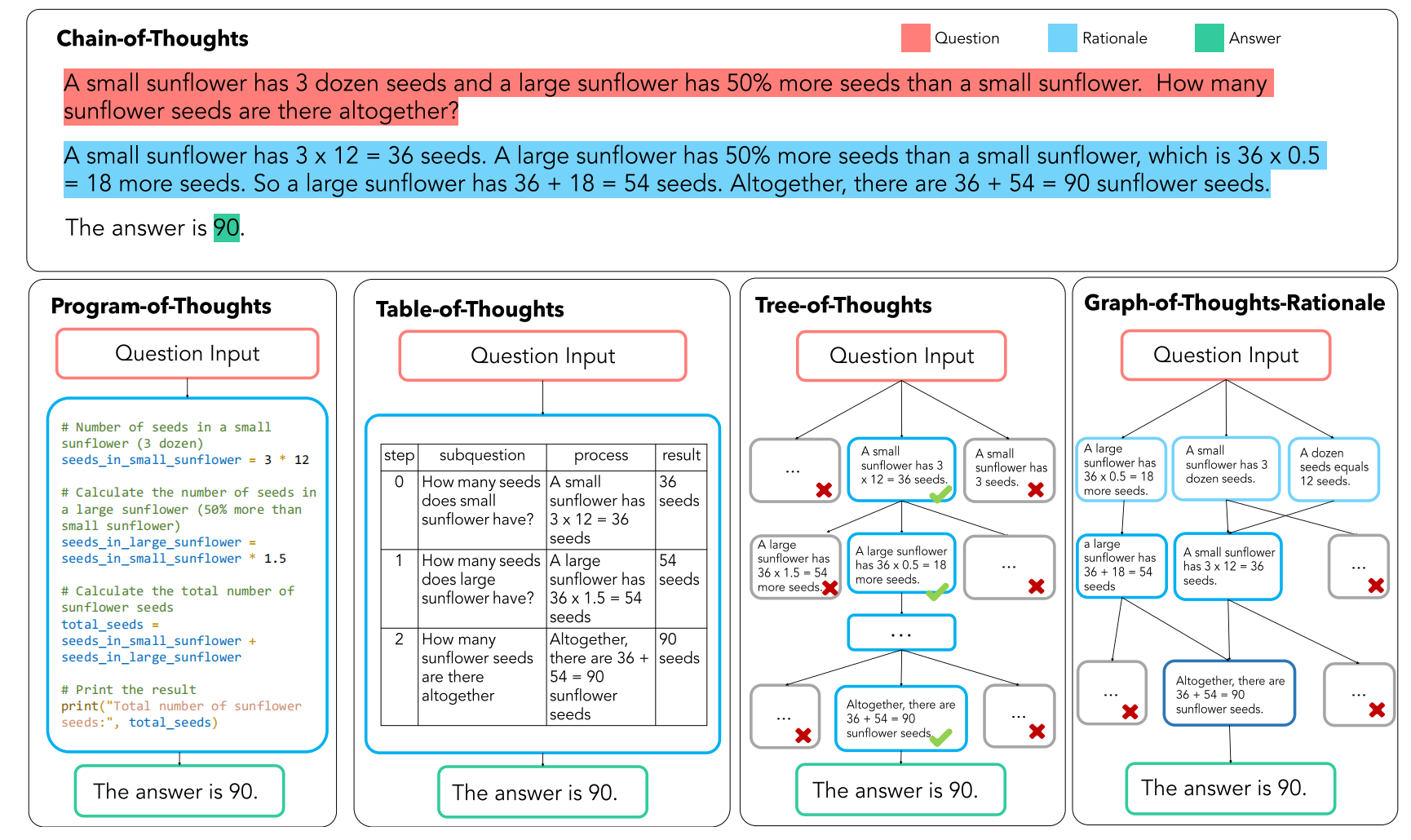
PoT:让大模型生成出编程语言在解释器运行
Tab-CoT:迫使大模型在每一步的推理中记录一个“∣步数∣子问题∣过程∣结果∣”的推理表格,并让大模型在推理时从生成的表格中提取答案
ToT:链式结构扩展为树形结构。ToT 让大模型在解决子问题时生成多个不同的答案选择,可以回溯
GoT:核心在于一个“控制器”,控制器处理对图的操作(GoO)以及图状态推理(GRS),其中 GoO 用于将一个给定的任务进行图分解,将一个任务分解为相互连接的节点-边关系,而 GRS 则负责维护大模型在 GoO 生成的图上的推理过程,记录当前步的状态,决策历史等等信息
Reasoning Aggregation
Self-consistency CoT:多次采样,通过投票等方法找到最优的答案
CoT Verification
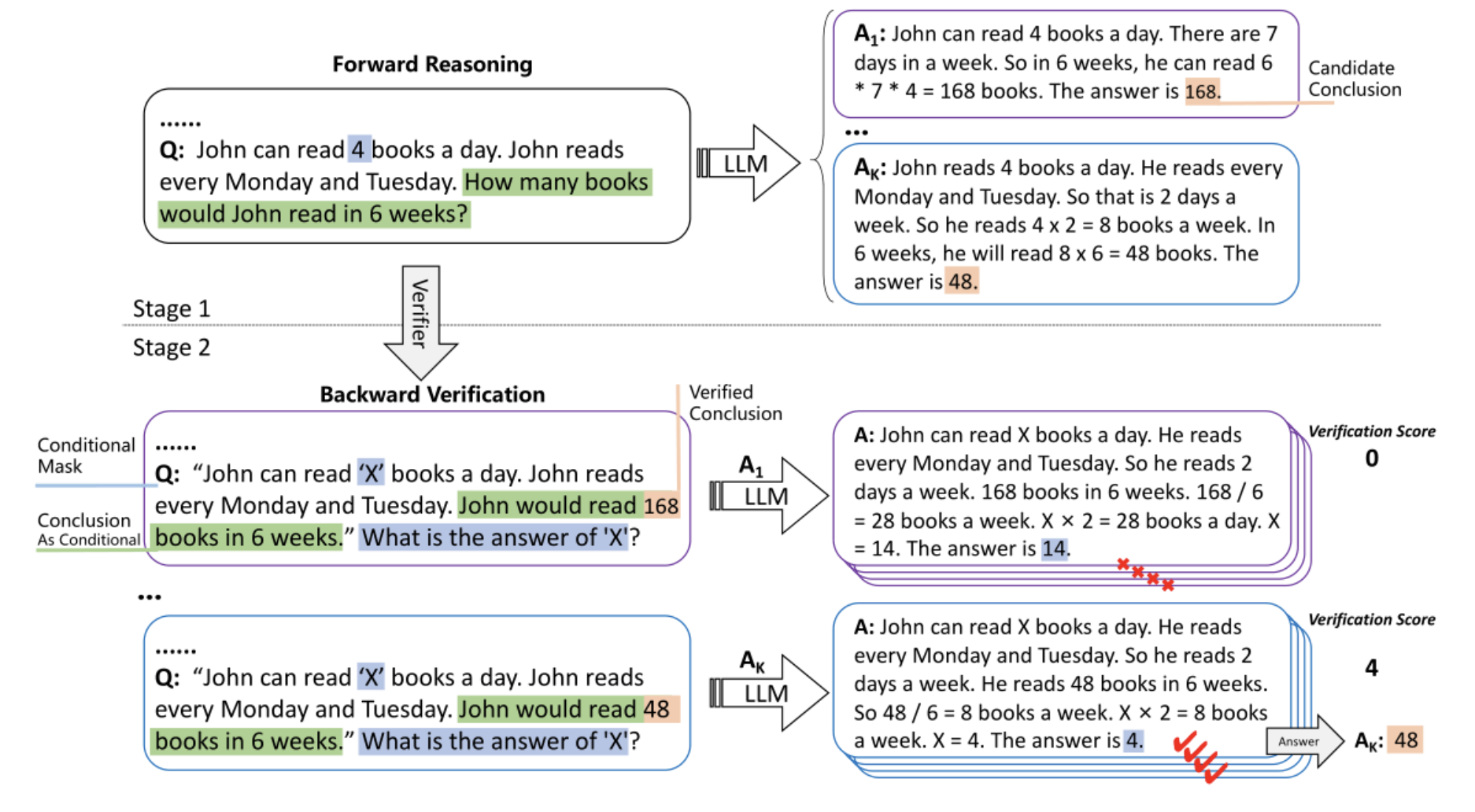
Self-verification: 在前向后向的反复问答中让大模型可以验证自己的回答,“后向”即使用CoT的结论作为条件来构建一个新的样本,并要求LLM重新预测被掩盖的原始条件
CRITIC :使得大模型可以交互式的引入外部工具来验证与修改自己的答案输出,经过大模型输出,外部工具验证,验证结果反馈,反馈修改四个循环的步骤加强 CoT 输出的可靠性。
AuRoRA:任务自适应与流程自动化,AuRoRA 从多个来源提取相关知识,将不同来源的知识进行组合、检查与提炼来修改初始 CoT,以提高CoT 的准确性与逻辑性。
CoT and AI Agent
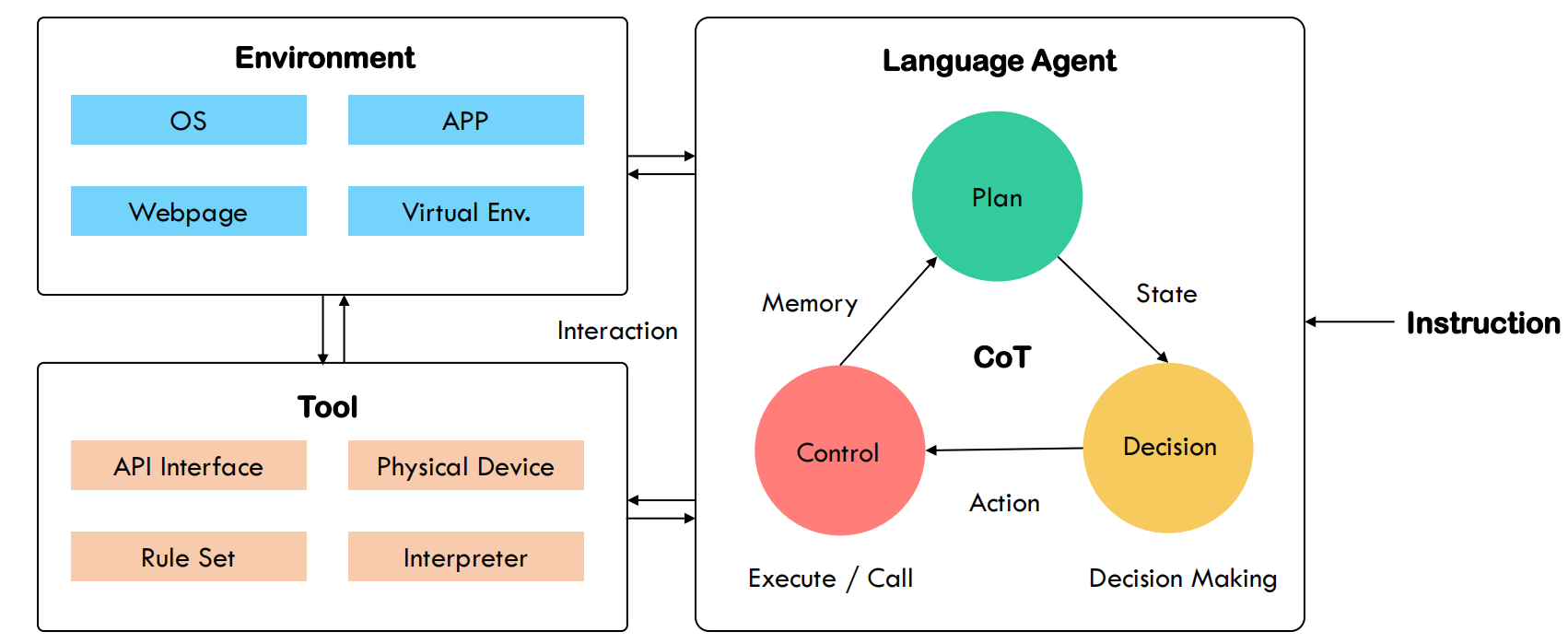
AI agents 依赖的3的方面能力:“感知”,“记忆”与“推理”
感知CoT
即从多种来源(环境、人类),多种模态的信息,如何进行“理解”,进行意图识别,最终生成CoT指令
多模态信息,需要LLM是一个多模态底座,或者有其他模态处理的信息,最后对齐在某个模态下
记忆CoT
短期记忆
任务强相关的
直接维护的上下文global信息
可以针对性提高LLM的long context能力
长期记忆
- 世界相关的,或者和用户相关(个性化)
- 存在模型的可训练参数里(参数化)
- 或者存在外部矢量数据库(非参数化)
记忆信息的操作
对记忆进行索引和crud,需要比较好的结构存储
(1)记忆树
- 节点离根的位置越近,记忆的抽象程度较高
(2)矢量数据库
推理CoT
CoT 主要的功能在于将计划、行动与观察相互结合,弥合推理与行动之间的差距
- 引导输出action
- 观察中整合历史action
- 观察中整合未来行动计划
refer: AgentBench
Insights
- 在未知领域中的泛化能力:尽管 AI Agent 的出现本身就拓展了大模型解决更加复杂未知领域问题的能力,但是由于缺乏与现实世界真正“具身”的交互,因此一个可以做到浏览网页的 Agent 是否通过同一套框架与工程手段就可以做到操控无人机编组,这一问题仍然悬而未决;
- Agent 的过度交互问题:为了完成任务,Agent 需要与环境进行大量复杂多步的交互,而一些研究也表明 Agent 很有可能会陷入到不断交互的循环陷井之中,在交互循环中无意义的空转,并且,由于 Agent 解决问题缺乏“效率”,因此由此生出的日志的存储与信息检索也将成为新的问题;
- 个性化 Agent:人手一个的私人智能助理是一个美好的畅想但是一个真正的个性化 Agent 的实现还面临许多问题,目前个性化 Agent 的研究有三条技术进路,分别是从定制化的 Prompt 出发,从微调出发以及从模型编辑出发,但是这些进路都有各自的问题,并且当下研究都主要聚焦于特定的问题背景,目前还不存在一套完整统一的解决方案;
- 多智能体社会:如何扩大大模型 Agent 的数量,以组成一个多智能体的社会用于观察“社会行为的涌现”也是一个非常有意思的方向,但是多智能体的计算开销是阻碍这一领域发展的关键问题;
- Agent 安全问题:当 Agent 逐步进入人们的日常生活,Agent 与 CoT 的安全性问题就必须得提上日程,譬如老生常谈得隐私泄露、权限滥用、有毒信息等等问题,此外,当 Agent 应用于现实世界后,此外,由于缺少现实世界真正多模态的反馈,譬如人类智能可以感受到“痛”,而 AI Agent 不会有这方面的信息输入,因此如何对完全不同质的两类主体进行“对齐”也将是关键问题;
- Agent 的评价:如何客观的评估一个 Agent 的能力也将是 AI Agent 发展带给我们的新问题,想想几年前 NLP 时代的数据集刷榜的评估方式,这种传统评价方式必然不适用于一个不断与外部环境打交道的 Agent。此外,一个做对了 99 步但生成答案错误的智能体可以本身能力要优于一个做错了 99 步但生成答案正确的智能体,因此 Agent 评价也呼唤除了评估执行任务的成功率以外的新指标、新方法。
7、记忆问题:在LLM context受限的情况下,设计什么样的上下文,维护什么样的信息?
Reference
[1] Zhang Z, Yao Y, Zhang A, et al. Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents[J]. arXiv preprint arXiv:2311.11797, 2023.
[2] https://zhuanlan.zhihu.com/p/668914454