《Paper Reading》Efficient Guided Generation for Large Language Models
Background
Guided Generation
- We want the LLM generation in a human-specified format
- Other than prompt, need to figure out more efficient end effective ways
Temp solutions
https://medium.com/productizing-language-models/guided-text-generation-with-large-language-models-d88fc3dcf4c
1.Prompt engineering and output parsers
Typical
Methods
- Format instructions: A method that returns a string
containing instructions for how the output of a language model should be
formatted.Here can use the pydantic model and "schema"
function(generate the json schema)
- Input the pydantic model format, get the instructions
- refer to the
get_format_instructionsin implementation example in LangChain
- Parser: A method that takes in a string (assumed to
be the response from a language model) and parses it into some
structure.
- Regex to find the json
- parse the json into a object(pydantic_object.parse_obj)
Benifits
- support any LLM (black box)
- Automatically generates the output instructions.
- Parses the generated JSON string into the model
Limitations
Json output is no guaranteed,since it's key in the first step (before the parser)
the more complex is the schema ,the more chances for the model to make mistake
context size too large for the instructions containing long schema desciption
2. Fill in values only
Typical
- JsonFormer:a wrapper around Hugging Face transformers that fills in these fixed tokens during the generation process and only delegates the generation of content tokens, the actual field values to the language model
Methods
The idea behind this method is to guide the text generation monitoring the logits and tokens sampling.Support 4 types:
- Generating booleans : compares logits for true and false
- Generating numbers: squash logits for non-digit tokens before sampling
- Generating strings: stops generation on second ”
- Generating arrays: compare logits for “[“, “,”, “]”
Benifits
- Efficiency. By generating only the content tokens and filling in the fixed tokens, this method is more efficient than generating a full JSON string and parsing it.
- Flexible and extendable. This library is built on top of the Hugging Face transformers library, making it compatible with any model that supports the Hugging Face interface.
- supports JSON schemas with nested objects.
- available in small and less capable LLM
Limitations
currently only supports a limited subset of JSON Schema types (number, boolean, string, array, object)
project is not actively maintained
3. Transform the geneation task into a finite-state machine transition
Typical
- Outlines(this work)
Methods
- Transform the geneation task into a finite-state machine transition
- modify the logits by mask the invalid token each time
Benifits
- The approach is model agnostic as long as you can mask the logits. Open-source LLMs can be used.
- Integration with HuggingFace transformers models.
Limitations
- it does not support APIs like OpenAI due to API limitation
- https://github.com/outlines-dev/outlines/issues/227
4. Domain Specific Language
Typical
- Guidance: provides a Domain Specific Language (DSL) for prompting. It merges templating and logic control making it possible to have more complex and clever prompts
Methods
- to do
Benifits
It provides a powerful Domain Specific Language for prompting making it easy to build the template for a JSON response.
doesn’t work well with small LLMs
Method
Firstly, review the task and give the math(procedure) description.
Secondly, come up with the method
Sampling Sequences

Guiding Generation

example:FSM masking for the regular expression ([0-9])?.?[0-9].
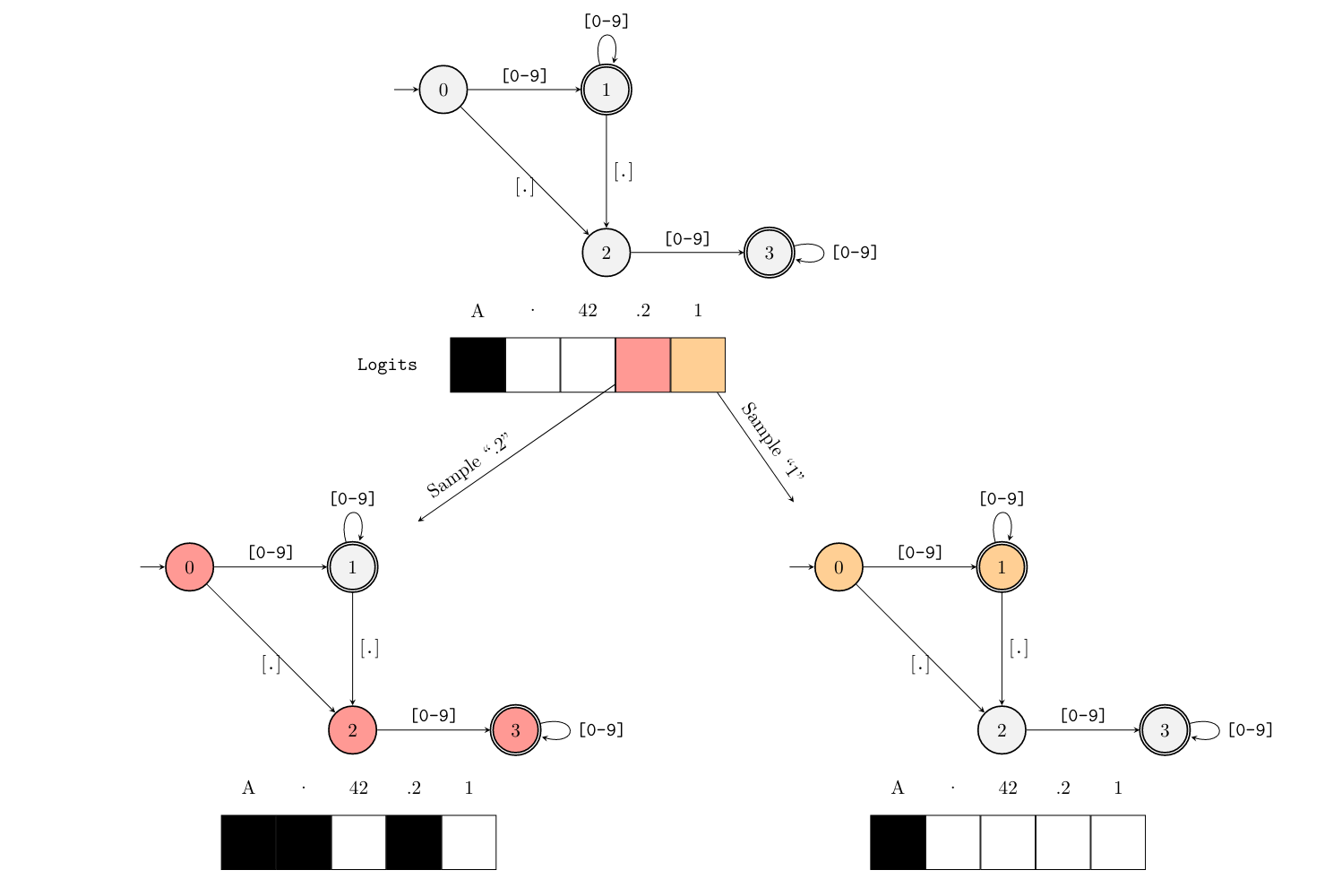
Implementation&Optimization
Target
- lower the complexity of masking
Extension of iterative parsing
- todo
- PDA(pushdown definite algorithm)
Questions&Inspirations
1、Do the num of decoding steps equal to original steps?
2、The implicit effects on LLM's inference,will it do harm to LLM since it has modified the logits output?
3、The hallucination situation?
- will this occur?Since it is a forward procedures with no turn back, will it generate the whole wrong message for the first wrong token?
1 | |
4、how to use it in training or fine-tuning?
- assisted generation during training may reduce the need for a model to learn syntactic details
- an alternative way to evaluate current models. To quantify the discrepancy between the masked logits generated outlines and the raw logits generated by the model. Which could in turn inform the training objective of a model
Reference
[1] Prompting is programming: A query language for large language models
[2] CODEP: Grammatical Seq2Seq Model for General-Purpose Code Generation
[3] https://medium.com/productizing-language-models/guided-text-generation-with-large-language-models-d88fc3dcf4c
[4] https://docs.pydantic.dev/latest/concepts/models/